本发明涉及无人机轨迹规划技术,特别是涉及一种基于上限置信区间算法的无人机群协同巡逻追踪轨迹规划方法。
随着无人机技术的发展,无人机的应用场景与用途也越来越广泛。由于无人机具有运动自由度高、有一定载荷能力、飞行较为稳定等特性,加上油动无人机续航较电动无人机有很大提升,无人机开始被应用于大区域范围巡逻监控,尤其是大型工业厂区、大农场等人工检查不便的地方。这些地方可能对人具有危险性、或者人工检查容易出现死角、或者范围太广使人工检查费时费力。在这类情况下,无人机群自动巡逻的优势就凸显出来。
无人机群自主巡逻的路径规划一直受到国内外学者的广泛关注,也产生了一些相关的研究与专利,但是它们都有各自的不足,使其难以将无人机巡逻与追踪做到完全自动化。比如在专利“一种通信约束下双无人机协同目标跟踪方法”中,作者虽考虑到了通信条件的约束,但是该方法仅限2架无人机,且有明显的长机僚机之分,当长机燃料耗尽需返航时,僚机也必须一起放弃跟踪任务,这可能导致失去目标位置。专利“多基站无人及连续跟踪系统及方法”中使用的基站—多无人及系统虽能使无人及群协同工作,但其追踪策略更适合于跟踪固定目标或行动较慢的目标,因为当某架无人及发现目标后其它飞机被设定为也赶往目标区域,但若能使得机群从多角度围追该目标,应该能获得更好的追踪效果。国外相关研究“cooperativepathplanningfortargettrackinginurbanenvironmentsusingunmannedairandgroundvehicles”虽然考虑了协同搜索与围追,但是没有加入无人机燃料量这一重要约束,以当前的无人机技术,无人机续航燃料有限导致的续航能力较低仍然是一个不可忽视的现实问题。
这种情况下就体现出基于上限置信区间算法的无人机群协同巡逻追踪轨迹规划方法在无人机巡逻轨迹规划问题中是非常前沿的。该方法主要基于人工智能技术,不仅同时考虑了无人机群在给定巡逻区域的智能搜索与追踪,使得机群围追目标以减少跟丢的情况,还加入了无人机续航时间的约束,合理地规划每架无人机的飞行与加油,使得整个团队能够协同完成巡逻与追踪的任务。
近年来,人工智能技术日益成熟,智能轨迹规划即是其中一个研究热点,在这些年的研究过程中,许多学者提出了针对特定环境、特定任务的无人机轨迹规划方法。上限置信区间算法(upperconfidenceboundapplytotree,uct)是由leventekocsis与csabaszepesvári在2006年提出的。很多学者应用此算法解决不同领域的决策问题。这一智能算法的优点是运算时间可控且鲁棒性强,可根据当前环境自我学习,进行更好的决策。但该算法要求决策过程完全可观,即无人机群必须使始终知道目标的位置信息,不能跟丢目标。由于这个限制,现有基于上限置信区间算法的无人机轨迹规划方法大多将任务分成两个部分:在未跟丢目标时使用上限置信区间算法进行追踪,而在跟丢目标后使用其它算法进行巡逻。这虽绕过了决策完全可观的限制,但降低了无人机群协同的智能程度,使无人机难以在跟丢目标后展开有效搜索以重新找到目标。
本发明为了充分发挥上限置信区间算法的优势,并没有将无人机群的巡逻与追踪分割成两个部分,而是通过引入目标概率模型,使得无论目标是否处于无人机群视野范围内,其位置信息都可以被有效描述,将决策过程变为完全可观。然后本发明结合目标概率模型与上限置信区间算法,设计了完整的轨迹规划学习算法为无人机决定运动方向,使机群智能协同完成区域巡逻与目标追踪的任务。
本发明技术解决问题,克服现有技术的不足,提供一种可实时运行的、鲁棒性强、高效准确的基于上限置信区间算法的无人机群协同巡逻追踪轨迹规划方法。
本发明提出的技术方案为:一种基于上限置信区间算法的无人机群协同巡逻追踪轨迹规划方法,实现步骤如下:
步骤1、在巡逻开始前输入巡逻区域大小、无人机数量、无人机视野范围、无人机最大飞行速度、加油站位置,用于步骤2中目标概率模型的初始化;
步骤2、创建并初始化目标概率模型。依据步骤1输入的参数,将无人机巡逻区域划分为以无人机视野面积的1/9为单位栅格的栅格阵,如图2所示,每个栅格记有目标处于该栅格位置的概率值,记该概率栅格阵为目标概率模型。初始化时将概率模型中的所有栅格的概率值设为相同,且概率之和为1。得到的目标概率模型将与步骤3中的队友模型一同在在步骤4中的轨迹规划学习算法里使用;
步骤3、创建并初始化队友模型。每架无人机都有一个对应的队友模型,每个模型记录该无人机的最大概率方向,最大概率方向考察无人机各方向栅格概率之和的大小,总共有4种,分别是{无人机北方的栅格概率之和最大,无人机南方的栅格概率之和最大,无人机东方的栅格概率之和最大,无人机西方的栅格概率之和最大}。队友模型记录无人机处于上述4种最大概率方向之一时,无人机分别选择{北,南,东,西,悬停}五个运动方向的频次。初始化时将上述4种最大概率方向中无人机的五个运动方向频次都设置为1。PG电子游戏下载得到的队友模型会在步骤4中的轨迹规划学习算法里使用;
步骤4、根据步骤3与步骤4得到的目标概率模型与队友模型,使用基于上限置信区间算法(upperconfidenceboundapplytotree,uct)的轨迹规划学习算法决定无人机运动方向,得到无人机的下一步运动方向即{北,南,东,西,悬停}五个运动方向之一。无人机按照该方向飞行;
步骤5、无人机探测其视野区域内是否存在目标,并依据探测结果采用基于量子概率模型的概率更新规则更新目标概率模型,更新后的目标概率模型会变更各个栅格的概率值,并被应用于下一次循环的步骤4中的轨迹规划学习算法;
步骤6、无人机观测队友位置与飞行方向,据此使用基于贝叶斯概率的队友学习方法更新队友模型,更新后的队友模型会更加准确地预测队友的行为,并被应用于下一循环的步骤4中的轨迹规划学习算法;
步骤7、利用步骤5、步骤6的更新结果,转到步骤4执行新的飞行方向决策,以确定无人机的下一步飞行方向。直至收到巡逻终止信号,表明任务完成。
所述步骤4中应用基于上限置信区间算法的轨迹规划学习算法决定无人机运动方向的方法如下:
步骤i)创建并初始化搜索树,用于记录步骤ii)与步骤iii)中无人机运动仿真的效果。搜索树的根结点表示当前无人机真实情况,树中各记录所处状态的目标概率模型、结点访问次数、结点平均奖励。这些数据将在步骤ii)及步骤iv)中使用,并由步骤iii)更新。初始化时搜索树只有根结点,该结点的目标概率模型即为实际的目标概率模型,结点访问次数与结点平均奖励都为0;
步骤ii)判断搜索次数是否达到最大搜索次数,若达到则若达到则停止搜索,并根据选择无人机运动方向式中q(s0,at)是根结点s0中无人机向at方向运动获取的平均奖励值,该奖励值将在步骤iii)中计算;若搜索次数未达到最大搜索次数则转至步骤iii)继续搜索;
步骤iii)判断当前结点是否达到最大搜索树深度,若达到则更新本次搜索经过的各结点st无人机向at方向运动获取的平均奖励值q(st,at),更新方法为:
式中n(st,at)为在结点st中无人机选择运动方向为at的频次,q为无人机群在步骤vi)中获取的各结点的机群奖励值。更新完成后转至步骤ii)开始下一次搜索;若当前结点未达到最大搜索树深度,则判断当前结点是否为搜索树的叶子结点,若是,则转到步骤iv),利用结点的平均奖励选择树扩展方向;若不是,则转到步骤v),通过试验得到新结点的平均奖励;
决定搜索树的扩展方向,式中a为具体运动方向,为{北,南,东,西,悬停}五个方向之一,a*即为实际选择的运动方向;s为当前仿真结点,n(s,a)为在结点s下决策运动方向为a的次数,n(s)为仿真中经过结点s的次数,cp为uct算法的调节参数,默认设置为0.5,q(st,at)为在结点st中无人机向at方向运动获取的平均奖励值。本步骤确定搜索树的扩展方向亦即无人机的运动方向为a*,然后转至步骤vi)预估队友运动方向以计算本步骤获取的机群奖励值;
步骤v)若步骤iii)判断当前结点是叶子结点,则采用随机仿真获取本次搜索的平均奖励值。即等概率地随机从{北,南,东,西,悬停}中决定一个运动方向a*并执行,然后转至步骤vi)预估队友运动方向以计算本步骤获取的机群奖励值;
步骤vi)预估队友的运动方向,具体方法为:根据该结点的目标概率模型,分别计算队友北,南,东,西四个方向的栅格概率之和,求出最大概率方向,然后以队友模型中该最大概率方向下选择{北,南,东,西,悬停}的频率为概率生成队友的运动方向方向;利用步骤iv)或步骤v)中获取的无人机运动方向以及本步骤的预估队友方向,计算无人机群本步获得的机群奖励值q。机群奖励值q即是无人机群在仿真过程中视野范围所覆盖的栅格概率之和减去该无人机因未及时加油而掉落的惩罚,惩罚公式为:
步骤vii)更新目标概率模型。具体方法为:各栅格向其邻接的且不在无人机群视野范围内的栅格均分其概率值。各栅格更新后的概率值即为其邻接栅格分给它的概率值之和,如图3所示,该步骤用于为下一循环中的步骤vi)提供新的目标概率模型。然后转至步骤ii)开始下一次搜索;
所述步骤5中用基于量子概率模型的概率更新规则更新目标概率模型的具体步骤如下:
步骤i)判断无人机群的视野范围内是否发现目标。若未发现目标则转至步骤ii)更新各栅格的概率值;否则转至步骤iii)标示目标所在位置;
步骤ii)更新目标概率模型。各栅格向其邻接的且不在无人机群视野范围内的栅格均分其概率值,各栅格更新后的概率值即为其邻接栅格分给它的概率值之和,如图3所示;
步骤iii)标示所发现目标的位置。将发现的目标所在栅格的概率值设为1,其它所有栅格的概率值设为0,如图4所示。
步骤i)求出各无人机此时北、南、东、西四个方向上的栅格概率之和,以找出概率之和最大的方向,记为最大概率方向si,为{无人机北方的栅格概率之和最大,无人机南方的栅格概率之和最大,无人机东方的栅格概率之和最大,无人机西方的栅格概率之和最大}中的一种。该最大概率方向用于更新步骤ii)中对应的频次;
步骤ii)依据队友实际做出的运动方向,更新队友在该最大概率方向下飞向各方向的频次,即根据下式更新:
式中nt(si)为无人机处于最大概率方向si的频次,nt(a,si)即为无人机在最大概率方向为si时选择运动方向为a的频次。
综上所述,本发明所述的基于上限置信区间算法的无人机群协同巡逻追踪轨迹规划方法,首先输入无人机巡逻区域、无人机数量、加油站位置等基本信息进行初始化,然后根据当前目标概率模型与队友模型,使用基于上限置信区间算法的轨迹规划学习算法决定无人机运动方向。各无人机在其视野范围内探测目标,并依据探测结果更新目标概率模型。之后无人机根据队友运行方向,使用基于贝叶斯概率的队友学习方法更新队友模型。机群各机独立地循环执行上述步骤按照规划的路径飞行与检测,在规定区域内巡逻并追踪可疑目标。
本发明与现有技术相比的优点在于:本发明具有鲁棒性好,计算时间可控、巡逻追踪效率高等特点,可广泛应用于厂区、农场等大区域自动化巡逻与追踪。uct算法使用蒙特卡洛方法进行决策,能同时考虑到队友位置、目标位置及本机油量等信息并进行综合决策,可以使得机群间相互合作,达到良好的巡逻、追踪效果。且由于uct算法鲁棒性强、运算时间可控,可在实际部署时根据机载设备运算能力与飞机速度,调整实际算法运行时间,保证最大程度地利用计算资源的同时进行实时计算,确保系统的稳定性。
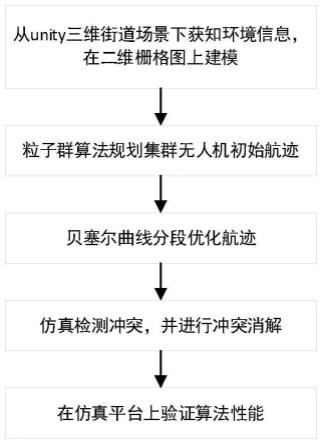
图1是本发明所述的基于上限置信区间算法的无人机群协同巡逻追踪轨迹规划过程;
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图及具体实施例对本发明作进一步地详细描述。
本发明所述的基于uct算法的无人机群协同巡逻追踪轨迹规划方法,首先输入无人机巡逻区域、无人机数量、加油站位置等基本信息进行初始化,然后根据当前目标概率模型与队友模型,使用基于uct的强化学习算法决定无人机运动方向。各无人机在其视野范围内探测目标,并依据探测结果更新目标概率模型。之后无人机根据队友运行方向,使用基于贝叶斯概率的队友学习方法更新队友模型。机群各机独立地循环执行上述步骤按照规划的路径飞行与检测,在规定区域内巡逻并追踪可疑目标。
步骤1)、在巡逻开始前输入巡逻区域大小、无人机数量、无人机视野范围、无人机最大飞行速度、加油站位置,用于步骤2)中目标概率模型的初始化;
步骤2)、创建并初始化目标概率模型。依据步骤1)输入的参数,将无人机巡逻区域划分为以无人机视野面积的1/9为单位栅格的栅格阵,如图2所示,每个栅格记有目标处于该栅格位置的概率值,记该概率栅格阵为目标概率模型。初始化时将概率模型中的所有栅格的概率值设为相同,且概率之和为1。得到的目标概率模型将与步骤3)中的队友模型一同在在步骤4)中的轨迹规划学习算法里使用;
步骤3)、创建并初始化队友模型。每架无人机都有一个对应的队友模型,每个模型记录该无人机的最大概率方向,最大概率方向考察无人机各方向栅格概率之和的大小,总共有4种,分别是{无人机北方的栅格概率之和最大,无人机南方的栅格概率之和最大,无人机东方的栅格概率之和最大,无人机西方的栅格概率之和最大}。队友模型记录无人机处于上述4种最大概率方向之一时,无人机分别选择{北,南,东,西,悬停}五个运动方向的频次。初始化时将上述4种最大概率方向中无人机的五个运动方向频次都设置为1。得到的队友模型会在步骤4)中的轨迹规划学习算法里使用;
步骤4)、根据步骤3)与步骤4)得到的目标概率模型与队友模型,使用基于上限置信区间算法(upperconfidenceboundapplytotree,uct)的轨迹规划学习算法决定无人机运动方向,得到无人机的下一步运动方向即{北,南,东,西,悬停}五个运动方向之一。无人机按照该方向飞行;
步骤5)、无人机探测其视野区域内是否存在目标,并依据探测结果采用基于量子概率模型的概率更新规则更新目标概率模型,更新后的目标概率模型会变更各个栅格的概率值,并被应用于下一次循环的步骤4)中的轨迹规划学习算法;
步骤6)、无人机观测队友位置与飞行方向,据此使用基于贝叶斯概率的队友学习方法更新队友模型,更新后的队友模型会更加准确地预测队友的行为,并被应用于下一循环的步骤4)中的轨迹规划学习算法;
步骤7)、利用步骤5)、步骤6)的更新结果,转到步骤4)执行新的飞行方向决策,以确定无人机的下一步飞行方向。直至收到巡逻终止信号,表明任务完成。
所述步骤4)中应用基于上限置信区间算法的轨迹规划学习算法决定无人机运动方向的方法如下:
步骤i)创建并初始化搜索树,用于记录步骤ii)与步骤iii)中无人机运动仿真的效果。搜索树的根结点表示当前无人机真实情况,树中各记录所处状态的目标概率模型、结点访问次数、结点平均奖励。这些数据将在步骤ii)及步骤iv)中使用,PG电子游戏下载并由步骤iii)更新。初始化时搜索树只有根结点,该结点的目标概率模型即为实际的目标概率模型,结点访问次数与结点平均奖励都为0;
步骤ii)判断搜索次数是否达到最大搜索次数,若达到则若达到则停止搜索,并根据选择无人机运动方向式中q(s0,at)是根结点s0中无人机向at方向运动获取的平均奖励值,该奖励值将在步骤iii)中计算;若搜索次数未达到最大搜索次数则转至步骤iii)继续搜索;
步骤iii)判断当前结点是否达到最大搜索树深度,若达到则更新本次搜索经过的各结点st无人机向at方向运动获取的平均奖励值q(st,at),更新方法为:
式中n(st,at)为在结点st中无人机选择运动方向为at的频次,q为无人机群在步骤vi)中获取的各结点的机群奖励值。更新完成后转至步骤ii)开始下一次搜索;若当前结点未达到最大搜索树深度,则判断当前结点是否为搜索树的叶子结点,若是,则转到步骤iv),利用结点的平均奖励选择树扩展方向;若不是,则转到步骤v),通过试验得到新结点的平均奖励;
决定搜索树的扩展方向,式中a为具体运动方向,为{北,南,东,西,悬停}五个方向之一,a*即为实际选择的运动方向;s为当前仿真结点,n(s,a)为在结点s下决策运动方向为a的次数,n(s)为仿真中经过结点s的次数,cp为uct算法的调节参数,默认设置为0.5,q(st,at)为在结点st中无人机向at方向运动获取的平均奖励值。本步骤确定搜索树的扩展方向亦即无人机的运动方向为a*,然后转至步骤vi)预估队友运动方向以计算本步骤获取的机群奖励值;
步骤v)若步骤iii)判断当前结点是叶子结点,则采用随机仿真获取本次搜索的平均奖励值。即等概率地随机从{北,南,东,西,悬停}中决定一个运动方向a*并执行,然后转至步骤vi)预估队友运动方向以计算本步骤获取的机群奖励值;
步骤vi)预估队友的运动方向,具体方法为:根据该结点的目标概率模型,分别计算队友北,南,东,西四个方向的栅格概率之和,求出最大概率方向,然后以队友模型中该最大概率方向下选择{北,南,东,西,悬停}的频率为概率生成队友的运动方向方向;利用步骤iv)或步骤v)中获取的无人机运动方向以及本步骤的预估队友方向,计算无人机群本步获得的机群奖励值q。机群奖励值q即是无人机群在仿真过程中视野范围所覆盖的栅格概率之和减去该无人机因未及时加油而掉落的惩罚,惩罚公式为:
步骤vii)更新目标概率模型。具体方法为:各栅格向其邻接的且不在无人机群视野范围内的栅格均分其概率值。各栅格更新后的概率值即为其邻接栅格分给它的概率值之和,如图3所示,该步骤用于为下一循环中的步骤vi)提供新的目标概率模型。然后转至步骤ii)开始下一次搜索;
所述步骤5)中用基于量子概率模型的概率更新规则更新目标概率模型的具体步骤如下:
步骤i)判断无人机群的视野范围内是否发现目标。若未发现目标则转至步骤ii)更新各栅格的概率值;否则转至步骤iii)标示目标所在位置;
步骤ii)更新目标概率模型。各栅格向其邻接的且不在无人机群视野范围内的栅格均分其概率值,各栅格更新后的概率值即为其邻接栅格分给它的概率值之和,如图3所示;
步骤iii)标示所发现目标的位置。将发现的目标所在栅格的概率值设为1,其它所有栅格的概率值设为0,如图4所示。
所述步骤6)中用基于贝叶斯概率的队友学习方法更新队友模型的具体步骤如下:
步骤i)求出各无人机此时北、南、东、西四个方向上的栅格概率之和,以找出概率之和最大的方向,记为最大概率方向si,为{无人机北方的栅格概率之和最大,无人机南方的栅格概率之和最大,无人机东方的栅格概率之和最大,无人机西方的栅格概率之和最大}中的一种。该最大概率方向用于更新步骤ii)中对应的频次;
步骤ii)依据队友实际做出的运动方向,更新队友在该最大概率方向下飞向各方向的频次,即根据下式更新:
式中nt(si)为无人机处于最大概率方向si的频次,nt(a,si)即为无人机在最大概率方向为si时选择运动方向为a的频次。
综上所述,以上仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。